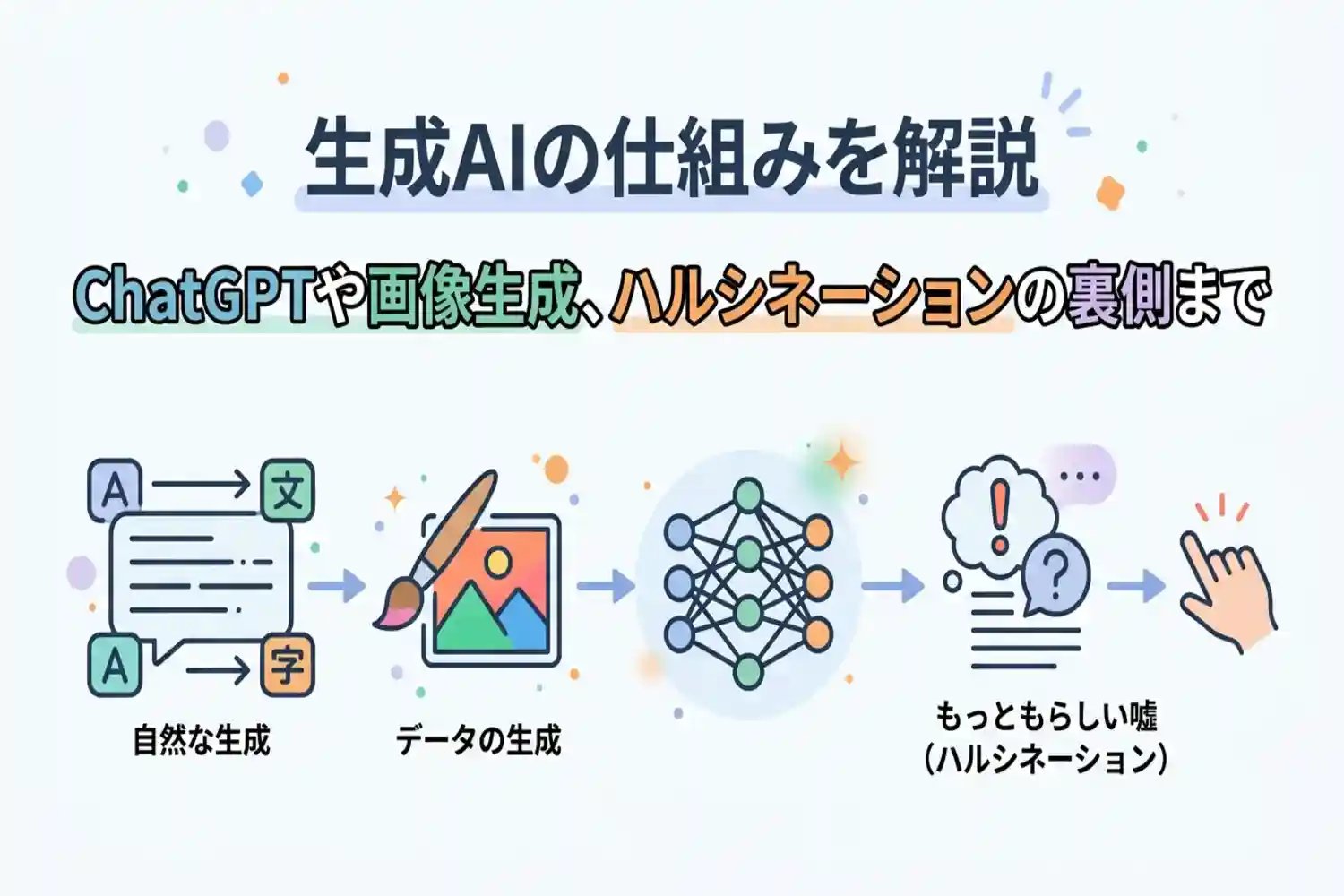
最近よく耳にする「生成AI」や「ChatGPT」ですが、その裏側でどのような仕組みが動いているのか気になりませんか。本記事では、生成AIが膨大なデータからテキストや画像を作り出す仕組みを、従来のAIとの違いを交えてわかりやすく解説します。また、大規模言語モデル(LLM)の構造や、なぜAIがもっともらしい嘘をつく(ハルシネーション)ことがあるのかといった疑問にもお答えします。生成AIの基礎知識を身につけることで、ビジネスや日常でのAI活用がさらにスムーズになるでしょう。
この記事で分かること
- 生成AIと従来のAIの仕組みの決定的な違い
- ChatGPTなどの文章生成AIが自然な言葉を作る裏側
- 画像生成AIや音声生成AIの基本的な仕組み
- 生成AIの学習方法と仕組みを学ぶメリット
生成AIとは何かその基本的な仕組みを解説
生成AI(ジェネレーティブAI)とは、あらかじめ学習した膨大なデータをもとに、テキストや画像、音声、プログラムコードなどの新しいコンテンツを自律的に作り出す人工知能のことです。近年の急激な事業拡大やテレワークの普及により、企業を取り巻くIT環境は急速に膨張しています。このような状況下において、生成AIは業務効率化や意思決定の迅速化を支える強力なテクノロジーとして、多くの企業で導入が進められています。
生成AIの根幹にあるのは、ディープラーニング(深層学習)と呼ばれる技術です。人間の脳の神経回路を模したニューラルネットワークを用いることで、データの中に潜む複雑なパターンや規則性を自動的に見つけ出します。これにより、単なるデータの検索や抽出にとどまらず、文脈に応じた自然な回答や、全く新しいデザインの生成が可能となっています。
従来のAIと生成AIの仕組みの違い
生成AIの仕組みを深く理解するためには、従来のAI(識別系AI)との違いを把握することが重要です。従来のAIは、主に与えられたデータに対する「認識」「分類」「予測」を得意としています。一方で生成AIは、学習したデータの特徴を抽出し、それらを組み合わせて「新しいものを生み出す」点に大きな違いがあります。
| 比較項目 | 従来のAI(識別系AI) | 生成AI(ジェネレーティブAI) |
|---|---|---|
| 主な役割 | データの分類、パターンの認識、数値の予測 | 新しいテキスト、画像、音声などの生成 |
| 仕組みのアプローチ | 入力データがどのカテゴリに属するかを確率で判定する | 学習データの構造や規則性を模倣し、未知のデータを出力する |
| ビジネスでの活用例 | スパムメールの検知、需要予測、不良品の画像検査 | 企画書の作成補助、プログラムコードの自動生成、デザイン制作 |
例えば、企業内で日々生成される膨大なログデータや各拠点からの報告データを扱う場合を考えてみましょう。従来のAIであれば「この通信はサイバー攻撃の可能性が高い」といった異常検知に用いられます。対して生成AIは、「検知された異常をもとに、どのような対策を講じるべきか」というレポートを自動的に作成するといった応用が可能です。
生成AIが膨大なデータを学習する仕組み
生成AIが人間のように自然な文章や精巧な画像を生成できるのは、「基盤モデル(ファウンデーションモデル)」と呼ばれる大規模なAIモデルを採用しているためです。この基盤モデルは、インターネット上に存在するテキストや画像など、極めて広範で多様なデータを事前学習(プレトレーニング)しています。
学習のプロセスは、主に以下のステップで進行します。
- データの収集と前処理:ウェブサイトや書籍などから膨大なデータを集め、ノイズを除去してAIが読み込める形式に整えます。
- 事前学習(プレトレーニング):ニューラルネットワークを用いて、単語の出現確率や画像の特徴などのパターンを大規模に学習させます。
- ファインチューニング(微調整):特定のタスクや企業の専門用語に合わせて追加学習を行い、出力の精度を高めます。
このように、生成AIは膨大なデータを栄養源として成長します。AIの性能向上には、質の高い学習データが不可欠であると一般的に言われています。しかし、企業が自社の業務に生成AIを組み込み、独自のデータを学習させる際には大きな課題が存在します。
M&Aやテレワークの普及によりIT環境が急膨張した結果、社内にどのようなPCやサーバーが存在し、それらがどのような状態にあるのかを正確に把握できていない企業は少なくありません。既存の資産管理ツールやExcelでの手作業による報告に頼っている状態では、データの集約に時間がかかり、AIに学習させる情報が常に過去のものとなってしまいます。このような「見えない」状態のままでは、サイバーリスクに対する意思決定が後手になるだけでなく、生成AIが出力する結果の正確性やセキュリティも担保できません。
生成AIのポテンシャルを最大限に引き出し、経営の見える化を迅速に行うためには、個別ツールの継ぎ足しによる管理から脱却する必要があります。すべての土台となるリアルタイムなエンドポイントの可視化と統制(コントロール)へと投資の舵を切ることが、これからのAI時代において企業が競争力を維持するための重要な鍵となります。


文章生成AIの仕組みとChatGPTの裏側
文章生成AIは、人間が書いたような自然な文章を作成する技術であり、業務効率化や新たなアイデアの創出に大きく貢献しています。経営層やIT部門の責任者にとって、この技術の裏側を理解することは、安全かつ効果的なAI活用の第一歩となります。ここでは、その中核となる技術と、代表的なAIがどのように機能しているのかを解説します。
大規模言語モデルが文章を作る仕組み
文章生成AIの基盤となっているのが、大規模言語モデル(LLM)と呼ばれる技術です。このモデルは、インターネット上の膨大なテキストデータを読み込み、「次に来る確率が最も高い単語」を予測することで文章を構築しています。
たとえば、「今日はとても良い」という入力があった場合、モデルは過去の学習データに基づいて「天気」「一日」「気分」などの候補の中から、文脈に最も適した単語を選択します。この予測を連続して行うことで、意味の通った長文を生成する仕組みです。
大規模言語モデルの学習プロセスは、主に以下のステップで進行します。
- 事前学習:膨大なテキストデータを読み込み、言語の規則性や一般的な知識を獲得する
- ファインチューニング:特定のタスク(翻訳、要約、質問応答など)に特化させるため、追加の学習を行う
- アライメント:人間の意図や倫理的基準に沿った回答ができるよう、出力の調整を行う
企業がこうした高度なAIを業務に組み込む際、従業員がどのような環境でAIを利用しているかを把握することが不可欠です。シャドーITによる未管理のAI利用を防ぐためには、すべての土台となるリアルタイムな可視化と統制が求められます。エンドポイントの状況を正確に把握できていない状態では、機密情報の漏洩などのサイバーリスクに対する意思決定が後手に回る恐れがあるためです。
ChatGPTが自然な会話を成立させる仕組み
文章生成AIの中でも、人間と対話しているかのような自然なやり取りを実現しているのがChatGPTです。この自然な会話の裏側には、単なる単語の予測を超えた高度な仕組みが存在します。
その中核となるのが、「人間のフィードバックからの強化学習(RLHF)」と呼ばれる手法です。AIが生成した複数の回答に対して、人間の評価者が「どれがより適切か」をランク付けし、その結果をAIに学習させます。これにより、AIは単に確率的に正しい文章を作るだけでなく、質問者の意図を汲み取り、より人間にとって自然で役立つ回答を生成できるようになります。
さらに、対話の文脈を保持する仕組みも重要です。ユーザーとの過去のやり取りを一時的に記憶し、それを踏まえた上で次の回答を生成するため、一問一答ではなく連続した会話が成立します。
以下の表は、従来のチャットボットと高度な文章生成AIの違いを整理したものです。
| 比較項目 | 従来のチャットボット | 高度な文章生成AI |
|---|---|---|
| 処理の仕組み | あらかじめ設定されたシナリオやルールに基づく | 膨大な学習データから確率的に適切な単語を予測し生成する |
| 文脈の理解 | 単発のキーワード反応が多く、前後の文脈理解が苦手 | 対話の履歴を保持し、複雑な文脈やニュアンスを理解して回答する |
| 対応できる範囲 | 想定された質問(FAQなど)のみ | 未知の質問や創造的なタスク(企画立案、要約など)にも対応可能 |
このような高度な仕組みを持つAIは、業務の生産性を飛躍的に向上させる可能性を秘めています。しかし、企業として安全に活用するためには、従業員が利用するPCやネットワーク環境のセキュリティ状態が常に可視化されている必要があります。個別ツールの継ぎ足しによる管理を脱却し、全社的なIT資産の一元管理へ投資の舵を切ることが、AI時代における安全な企業経営の基盤となります。
画像生成AIと音声生成AIの仕組み
文章生成AIだけでなく、画像や音声を生成するAIもビジネスの現場で急速に普及しています。これらのAIは、どのような技術的基盤に基づいて動作しているのでしょうか。ここでは、画像生成AIと音声生成AIの裏側にある仕組みを解説します。
画像生成AIがノイズから絵を描く仕組み
近年の画像生成AIの多くは、「拡散モデル(Diffusion Model)」と呼ばれる技術を採用しています。この技術は、画像に意図的にノイズ(乱雑なデータ)を加え、それを元の画像に戻すプロセスを学習することで、全く新しい画像を生成する仕組みです。
具体的には、以下のステップで学習と生成が行われます。
- 大量の画像データと、それを説明するテキストデータをAIに読み込ませる
- 画像に徐々にノイズを加え、完全にランダムなノイズにする過程を学習する
- ランダムなノイズから、テキストの指示に従ってノイズを除去し、意味のある画像を復元する過程を学習する
このプロセスにより、ユーザーが入力したテキスト(プロンプト)の指示に沿って、ノイズから徐々に鮮明な画像を浮かび上がらせることが可能になります。また、拡散モデルが登場する以前は、「GAN(敵対的生成ネットワーク)」という技術が主流でした。GANは、画像を生成するAIと、それが本物か偽物かを見破るAIを競わせることで、精度の高い画像を生成する仕組みです。
| 技術名 | 主な特徴 | 得意な処理 |
|---|---|---|
| 拡散モデル | ノイズの追加と除去の過程を学習する | テキストからの高精細な画像生成 |
| GAN | 生成役と判定役のAIを競わせる | 実在するデータに近いリアルな画像の生成 |
音声生成AIが人間の声を再現する仕組み
音声生成AIは、人間の声の波形やイントネーション、リズムなどの特徴を学習し、テキストデータから自然な音声を合成する技術です。従来の音声合成は、あらかじめ録音された短い音声を繋ぎ合わせる方式が主流でしたが、現在の生成AIはディープラーニング(深層学習)を用いて、より人間に近い滑らかな発話を可能にしています。
音声生成のプロセスは、主に以下の要素で構成されています。
- テキスト解析:入力された文章の読み方やアクセントを解析する
- 音響モデル:解析されたデータをもとに、声の高さや長さを予測する
- ボコーダー:予測されたデータから実際の音声波形を生成する
特に、人間の声の微細な揺らぎや感情表現まで再現できるようになったことは、音声生成AIの大きな進化と言えます。一方で、この技術の高度化により、特定の人物の声を無断で再現するディープフェイクなどのセキュリティリスクも懸念されています。
新しいテクノロジーが社内に次々と持ち込まれる環境下において、企業がこれらの技術を安全に活用するためには、個別ツールの導入にとどまらず、社内のあらゆるIT資産やデータの動きをリアルタイムに把握できる可視化と統制の仕組みへの投資が不可欠です。
よくある質問(FAQ)
生成AIはどのようにして学習する仕組みですか
生成AIは、インターネット上に存在する膨大なテキストや画像、音声などのデータを収集し、それらのパターンや規則性を「ニューラルネットワーク」と呼ばれる人間の脳の神経回路を模したモデルを用いて学習します。この学習プロセスは、主に「事前学習」と「ファインチューニング(微調整)」の2段階に分かれています。
事前学習では、大量のデータから言語の文法や一般的な知識、データ同士の関連性を自己教師あり学習によって獲得します。その後、特定の業務や目的に合わせて人間のフィードバックを交えながらファインチューニングを行うことで、より精度が高く、意図に沿った自然な出力を生成できる仕組みとなっています。
ChatGPTの仕組みは他の生成AIと同じですか
「膨大なデータから特徴を学習し、入力に対して確率的に最も適切な結果を出力する」という根本的な仕組みは共通していますが、扱うデータの種類や目的によって背後にある技術(アーキテクチャ)は異なります。ChatGPTなどの文章生成AIと、その他の生成AIの違いは以下の通りです。
| 生成AIの種類 | 主な用途 | 中核となる技術・仕組み |
|---|---|---|
| 文章生成AI(ChatGPTなど) | 文章の作成、要約、翻訳、対話 | Transformerなどの大規模言語モデル(LLM) |
| 画像生成AI | イラストや写真の生成、加工 | 拡散モデル(Diffusion Model)など |
| 音声生成AI | 音声合成、楽曲の生成 | 波形生成モデル、音声合成技術 |
生成AIの仕組みを学ぶメリットは何ですか
経営層やIT部門の責任者が生成AIの仕組みを正しく理解する最大のメリットは、自社のIT環境における適切なガバナンスの構築と、本質的なIT投資の判断が可能になる点にあります。具体的なメリットは以下の通りです。
- 生成AIの得意・不得意を把握し、業務効率化の正しい適用範囲を見極められる
- 入力データがどのように処理されるかを理解することで、情報漏えいなどのセキュリティリスクを未然に防げる
- AI活用を支えるための、社内ITインフラの現状把握と整備の必要性に気づくことができる
急激な事業拡大やテレワークの普及により、社内のIT環境が複雑化している企業において、新しいテクノロジーを安全に導入するためには、まずすべての土台となるリアルタイムな可視化と統制へ投資の舵を切ることが不可欠です。
生成AIは嘘をつく仕組みになっているのですか
生成AIは意図的に嘘をつくように設計されているわけではありませんが、仕組み上、事実とは異なる情報をもっともらしく出力してしまう現象(ハルシネーション)が発生することがあります。これは、AIが事実確認を行っているわけではなく、学習した膨大なデータの中から「確率的に次に来る可能性が高い単語」を繋ぎ合わせて文章を生成しているためです。
そのため、業務において生成AIを利用する際は、出力された結果をそのまま鵜呑みにするのではなく、必ず人間が事実確認(ファクトチェック)を行うプロセスを組み込むことが重要です。
無料で使える生成AIの仕組みはどうなっていますか
無料で提供されているコンシューマー向けの生成AIサービスの多くは、ユーザーが入力したプロンプト(指示内容)やデータを、AIモデルのさらなる精度向上のための再学習データとして利用する仕組みを採用しています。そのため、従業員が業務上の機密情報や個人情報を無料の生成AIに入力してしまうと、意図せず外部に情報が漏えいする重大なリスクが生じます。
このようなシャドーIT(会社が把握していないITツールの利用)を防ぐためには、組織としての明確な利用ガイドラインの策定が必要です。しかし、ガイドラインだけでは実効性が伴いません。個別ツールの継ぎ足しによる場当たり的な対策を止め、社内にどのようなデバイスが存在し、誰がどのサービスを利用しているのかを正確に把握するエンドポイントの全体最適と一元管理を実現することが、経営の見える化とサイバーリスク対策の第一歩となります。
生成AIはどのようにして学習する仕組みですか
生成AIが人間のように自然な文章やデータを生成できる背景には、膨大なデータを用いた段階的な学習プロセスが存在します。ここでは、生成AIが具体的にどのような仕組みで学習を行っているのかを解説します。
生成AIの学習プロセスを支える3つの段階
生成AIの学習は、主に「事前学習」「ファインチューニング」「強化学習」という3つのステップで構成されています。それぞれの段階で異なる目的と手法が用いられます。
1. 事前学習(Pre-training)
事前学習は、生成AIの基礎となる知識を構築するプロセスです。インターネット上の膨大なテキストデータや画像データを読み込み、言葉の規則性やデータの特徴を学習します。この段階で、AIは「次に来る単語を予測する」などの基本的な能力を獲得します。
2. ファインチューニング(Fine-tuning)
事前学習を終えたモデルに対し、特定のタスクや目的に合わせた微調整を行うのがファインチューニングです。例えば、企業が自社の業務マニュアルや専門用語をAIに学習させることで、特定の業務に特化した回答ができるようになります。
3. 人間のフィードバックからの強化学習(RLHF)
AIの出力がより人間にとって自然で安全なものになるよう、人間の評価を基に学習を重ねる手法です。不適切な発言や偏見を含む出力を抑制し、実用性の高い回答を生成するための重要なステップとなります。
機械学習の手法と学習データの種類
生成AIの学習には、主に以下のような機械学習の手法が用いられます。
- 教師あり学習:正解ラベルが付与されたデータを用いて学習する手法
- 教師なし学習:正解ラベルのないデータから規則性や特徴を見つけ出す手法
- 強化学習:試行錯誤を通じて最適な行動方針を学習する手法
これらの学習手法とデータの関係性について、以下の表にまとめます。
| 学習手法 | 使用するデータの状態 | 生成AIにおける主な用途 |
|---|---|---|
| 教師あり学習 | 正解ラベルが付与されたデータ | ファインチューニング、特定のタスクへの最適化 |
| 教師なし学習 | 正解ラベルのない膨大なデータ | 事前学習、言語モデルの基礎構築 |
| 強化学習 | 報酬(人間の評価など)に基づくデータ | 人間のフィードバックからの強化学習による安全性向上 |
企業のIT環境と生成AIの学習における注意点
生成AIを企業内で活用し、自社データを学習させる際には、社内にどのようなIT資産やデータが、今どういう状態で存在するのかを正確に把握しておくことが不可欠です。事業拡大やテレワークの普及によりIT環境が急膨張した大企業においては、各拠点や子会社にデータが散在し、情報の集約に数日や数週間かかってしまうケースが少なくありません。
AIに質の高い学習を行わせ、情報漏えいなどのサイバーリスクを防ぐためには、既存の資産管理ツールや手作業での報告といった個別ツールの継ぎ足しを止め、すべての土台となるリアルタイムな可視化と統制へ投資の舵を切ることが重要です。全社最適となる一元管理が実現されて初めて、生成AIは企業にとって安全かつ真の価値をもたらします。なお、生成AIの基本的な仕組みや社会的な動向については、総務省の令和5年版情報通信白書などでも詳しく解説されています。
ChatGPTの仕組みは他の生成AIと同じですか
結論から申し上げますと、ChatGPTをはじめとする文章生成AIと、画像や音声などを生成する他のAIとでは、基盤となるアプローチに共通点はありますが、具体的な仕組みや学習プロセスは異なります。
生成AIは、テキスト、画像、音声など、出力するデータの種類(モダリティ)に応じて最適なアルゴリズムが採用されています。企業が業務効率化やデジタルトランスフォーメーションを推進するうえで、これらの仕組みの違いを理解することは、適切なツールの選定やセキュアな運用環境の構築において非常に重要です。
基盤となるモデルの違い
ChatGPTは大規模言語モデルと呼ばれる技術をベースにしています。これは、膨大なテキストデータを学習し、次に来る確率が最も高い単語を予測して文章を生成する仕組みです。一方、画像生成AIでは拡散モデルなどが主流となっており、ノイズから徐々に画像をクリアにしていくプロセスで生成を行います。
以下の表は、ChatGPTに代表される文章生成AIと、他の代表的な生成AIの仕組みの違いを整理したものです。
| 生成AIの種類 | 代表的な技術・モデル | 学習データの種類 | 生成のプロセス |
|---|---|---|---|
| 文章生成AI(ChatGPTなど) | 大規模言語モデル(LLM) | ウェブ上のテキスト、書籍、記事など | 文脈を理解し、次に来る適切な単語を確率的に予測してテキストを出力 |
| 画像生成AI | 拡散モデル(Diffusion Model)など | 画像とテキストのペアデータ | ランダムなノイズから、テキストの指示に沿って画像を復元・生成 |
| 音声生成AI | 音声合成モデルなど | 人間の音声データ、テキストデータ | テキスト情報を音響特徴量に変換し、自然な波形として音声を出力 |
企業利用における管理と統制の重要性
このように、生成AIは出力する目的によって異なる仕組みで動いています。しかし、どの生成AIを利用する場合でも共通して求められるのが、入力するデータの取り扱いとセキュリティの確保です。
とくに大企業においては、従業員がどのような生成AIツールを利用し、どのようなデータを入力しているのかをリアルタイムに把握することが不可欠です。社内のIT資産やツールの利用状況が可視化されていない状態では、情報漏えいやコンプライアンス違反のリスクが極めて高まります。
生成AIを安全かつ効果的に活用するためには、個別ツールの導入を場当たり的に進めるのではなく、以下のような全社的な統制の土台を築くことが求められます。
- 社内で利用されているすべてのIT資産とソフトウェアのリアルタイムな可視化
- エンドポイントにおけるセキュリティ対策とパッチ適用状況の一元管理
- 生成AIへの機密情報の入力を防ぐためのガイドライン策定と技術的な制御
生成AIの仕組みの違いを正しく理解するとともに、すべての土台となるリアルタイムな可視化と統制へ投資の舵を切ることが、今後の企業成長とサイバーリスク対策において不可欠です。
生成AIの仕組みを学ぶメリットは何ですか
生成AIを単なる便利なツールとして使うだけでなく、その裏側にある仕組みを理解しておくことには多くの利点があります。仕組みを学ぶことで得られる具体的なメリットは、大きく分けて以下の3つです。
- 意図した通りの質の高い回答を引き出せるようになる
- セキュリティリスクや情報の誤りを適切に回避できる
- 自社の業務や個人のタスクに最適なAIツールを選択できる
質の高いプロンプトを作成しやすくなる
生成AIがどのように言葉を予測し、文脈を捉えているのかを理解すると、AIにとって分かりやすい指示(プロンプト)を作成できるようになります。大規模言語モデルが確率に基づいて次の単語を出力しているという前提を知っていれば、AIが文脈を絞り込みやすいように具体的な条件や背景情報を与えることが重要であると自然に理解できるはずです。結果として、何度も指示を出し直す手間が省け、アウトプットの精度が飛躍的に向上します。
AIの限界を理解しリスクを回避できる
生成AIの仕組みを知ることは、AIが苦手とする領域や潜在的なリスクを把握することにもつながります。例えば、入力したデータがAIの学習に利用される可能性があるという仕組みを理解していれば、機密情報や個人情報の入力を控えるといった適切なセキュリティ対策を講じることができます。
実際に、一般社団法人日本ディープラーニング協会(JDLA)も生成AIの利用に関するガイドラインを公開しており、組織として仕組みを理解した上でリスクマネジメントに取り組むことが推奨されています。
業務効率化やビジネスへの応用がスムーズになる
テキスト生成、画像生成、音声生成など、それぞれのAIがどのようなアルゴリズムで動いているのかを知ることで、目的に合った適切なツールを選定できるようになります。以下の表は、仕組みの理解度がAIの活用にどう影響するかをまとめたものです。
| 活用シーン | 仕組みを知らない場合 | 仕組みを理解している場合 |
|---|---|---|
| ツールの選定 | 話題になっているAIをとりあえず使う | 業務の目的に最適なモデルやサービスを選択できる |
| エラーへの対応 | 望まない結果が出た際に解決策が分からない | 原因を推測し、プロンプトやパラメータを調整できる |
| 情報の信頼性評価 | AIの回答をすべて事実として鵜呑みにしてしまう | 情報源の確認(ファクトチェック)を怠らずに活用できる |
このように、生成AIの仕組みを学ぶことは、AIを安全かつ最大限に活用するための土台となります。仕組みをブラックボックスのままにせず、基本的な動作原理を押さえておくことが、これからのデジタル社会を生き抜く上で大きな強みとなるでしょう。
生成AIは嘘をつく仕組みになっているのですか
生成AIを利用していると、時折事実とは異なるもっともらしい回答を出力することがあります。これはAIが意図的に嘘をついているわけではなく、文章を生成する仕組みそのものに起因する現象です。
もっともらしい嘘「ハルシネーション」とは
生成AIが事実に基づかない情報を生成してしまう現象は「ハルシネーション(幻覚)」と呼ばれています。大規模言語モデルは、入力された指示に対して、学習した膨大なデータの中から確率的に最も適切と思われる単語を次々と予測して繋ぎ合わせる仕組みで文章を作成します。
つまり、AIは情報の意味や真偽を人間のように理解して回答しているのではなく、あくまで統計的な確率に基づいて文章を生成しているに過ぎません。そのため、事実確認を行う機能が備わっていない限り、誤った情報であっても自信満々に出力してしまうのです。
ハルシネーションを引き起こす主な要因
確率的な予測が事実と異なる結果を生む主な要因としては、以下のようなものが挙げられます。
- 学習データ自体に誤りや偏りが含まれている場合
- 学習時点以降の最新情報がデータに含まれていない場合
- 専門性が高く、学習データが極端に少ない分野の質問である場合
これらの要因と仕組み上の理由を整理すると、以下のようになります。
| 要因 | 仕組み上の理由 |
|---|---|
| 学習データの質と量 | インターネット上の不正確な情報や偏ったデータをそのまま学習のベースとしているため。 |
| 情報の鮮度 | 学習時点以降の最新情報を持たないため、過去のデータから無理に推論して回答を生成しようとするため。 |
| 文脈の誤解釈 | ユーザーの指示の意図を正確に捉えられず、関連性の低いデータ同士を確率論で結合してしまうため。 |
企業利用におけるリスクと統制の重要性
企業において生成AIを活用する際、このハルシネーションは業務上の重大なリスクとなり得ます。誤った情報に基づいて経営判断を下したり、不正確な情報を顧客に提供してしまったりする可能性があるためです。 生成AIの課題として、偽情報の拡散やハルシネーションのリスクは各方面で指摘されています。
こうしたリスクを低減するためには、生成AIの出力結果を人間が必ず確認する運用ルールを設けることが不可欠です。さらに、従業員が独自の判断で様々な生成AIツールを利用する状況は、情報漏洩や誤情報の蔓延といったセキュリティリスクを増大させます。各拠点や部門で個別にツールを導入する継ぎ足しの管理を止め、全社的なIT環境のリアルタイムな可視化と一元的な統制へ投資の舵を切ることが、最新技術を安全かつ有効に活用するための大前提となります。
無料で使える生成AIの仕組みはどうなっていますか
現在、多くの生成AIサービスが無料で一般公開されていますが、その裏側には明確なビジネスモデルとシステム上の仕組みが存在します。企業でこれらの無料サービスを利用する際には、なぜ無料で使えるのか、そして入力したデータがどのように処理されるのかを正しく理解しておくことが不可欠です。
無料提供を支えるビジネスモデルと学習データの仕組み
無料で提供されている生成AIの多くは、「フリーミアム(Freemium)モデル」を採用しています。基本的な文章生成や画像生成の機能は無料で提供し、より高度な推論能力を持つ最新モデルや、高速な処理、API連携などの拡張機能を必要とするユーザーに対して有料プランを促す仕組みです。
さらに重要な点として、無料版の生成AIでは、ユーザーが入力したプロンプト(指示文)やデータが、AIモデルのさらなる精度向上のための学習データとして利用される仕組みになっていることが一般的です。サービス提供者は、世界中のユーザーから日々入力される膨大なテキストデータを収集し、次世代モデルの再学習に活用することで、AIの性能を継続的に進化させています。
| 項目 | 無料版の生成AI | 有料版・法人向け生成AI |
|---|---|---|
| 主な目的 | 基本機能の提供、学習データの収集 | 高度な機能の提供、業務効率化の支援 |
| 入力データの扱い | 原則としてAIの再学習に利用される | 学習に利用されない(オプトアウトが標準) |
| セキュリティ統制 | 個人向けであり管理機能が乏しい | 企業向けのユーザー管理やログ監視が可能 |
企業利用における無料生成AIのセキュリティリスク
このような無料版の仕組みを踏まえると、企業における業務利用には大きなセキュリティリスクが伴います。従業員が業務効率化のために、未承認の無料生成AIに機密情報や顧客データ、ソースコードなどを入力してしまうと、それらの情報がAIの学習データとして取り込まれ、意図せず第三者への情報漏洩に繋がる恐れがあります。
特に、急激な事業拡大やテレワークの普及、M&AなどによりIT環境が急膨張している企業では、社内にどのようなIT資産(PCやサーバー)が存在し、どのデバイスからどのようなクラウドサービスが利用されているのか、全社的な一元管理が困難になっています。 情報処理推進機構(IPA)も毎年 セキュリティ10大脅威を発表しており、情報漏洩は組織にとって継続的な脅威の一つとされています。見えないIT資産(シャドーIT)の放置は経営上の重大なリスクです。
シャドーITを防ぐためのリアルタイムな可視化と統制
各拠点や子会社からの手作業による報告や、表計算ソフトに頼った既存の資産管理では、情報の集約に数日〜数週間かかり、データが常に過去のものになってしまいます。「見えない」状態では、従業員による無料生成AIの無断利用といったサイバーリスクに対する意思決定や対策が常に後手後手に回ってしまいます。
無料の生成AIが持つリスクを正しくコントロールし、安全な業務環境を構築するためには、個別ツールの継ぎ足しを止める必要があります。経営層やIT部門の責任者は、すべての土台となるエンドポイントのリアルタイムな可視化と統制(コントロール)へ投資の舵を切ることが求められます。
具体的には、以下のような仕組みを全社的に整備することが重要です。
- 全社に点在するPCやサーバーの稼働状況とソフトウェアの利用状況をリアルタイムに把握する
- 未承認の無料生成AIサービスへのアクセスを検知し、必要に応じて制御する
- OSやアプリケーションの脆弱性の有無、パッチ適用状況を一元管理し、常に最新のセキュリティ状態を保つ
生成AIの利便性は非常に高いものの、無料版の仕組みを理解せずに放置することは危険です。まずは自社のIT環境を正確に把握し、エンドポイント管理の真の価値を引き出すことで、安全かつ効果的なAI活用に向けた盤石な基盤を築くことが不可欠です。
生成ai 仕組みに関するよくある質問
生成AIはどのようにして学習する仕組みですか?
インターネット上の膨大なテキストや画像データを収集し、データ内のパターンや規則性を確率的に分析することで学習します。
ChatGPTの仕組みは他の生成AIと同じですか?
基本となる大規模言語モデルの仕組みは共通していますが、人間との自然な対話に特化した強化学習が行われている点で異なります。
生成AIの仕組みを学ぶメリットは何ですか?
AIの得意なことと苦手なことを正確に把握できるため、業務効率化や新しいアイデア出しにAIをより効果的に活用できるようになります。
生成AIは嘘をつく仕組みになっているのですか?
嘘をつく意図はありませんが、確率に基づいてもっともらしい言葉を繋ぎ合わせる仕組みのため、事実とは異なる内容を出力するハルシネーションという現象が起こります。
無料で使える生成AIの仕組みはどうなっていますか?
基本的な仕組みは有料版と同じですが、一度に処理できるデータ量や使用できるモデルのバージョンが制限されていることが一般的です。
まとめ
この記事では、生成AIの仕組みやChatGPTが動く裏側について解説しました。従来のAIとは異なり、新しいコンテンツを生み出せるのが生成AIの大きな特徴です。
- 生成AIは膨大なデータを学習し、確率に基づいて最適な情報を出力する
- ChatGPTは大規模言語モデルを活用し、自然な対話を成立させている
- 画像や音声の生成AIも、ノイズの除去や波形の学習といった独自の仕組みで動いている
- 仕組み上、事実と異なる情報を出力する可能性があるため注意が必要である
生成AIの仕組みを理解することで、ビジネスや日常の作業を大幅に効率化できます。まずは無料のChatGPTなどに触れ、実際にプロンプトを入力して生成AIの可能性を体験してみましょう。